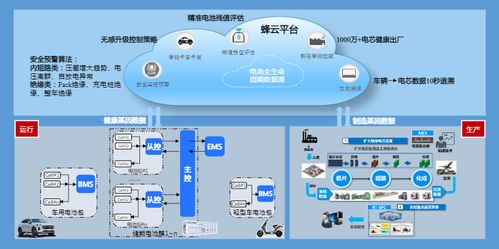
隨著工業4.0時代的到來,制造型企業正積極向智能化、數字化方向轉型。搭建數字化生產車間并有效應用工業互聯網數據服務,已成為提升企業競爭力的關鍵路徑。本文將系統闡述制造型企業如何搭建數字化生產車間,并深度整合工業互聯網數據服務,實現生產全流程的優化與升級。
一、數字化生產車間的核心構建要素
數字化生產車間的建設需從硬件設施、軟件系統和數據基礎三個維度同步推進:
- 智能設備層:引入工業機器人、智能傳感設備、AGV小車等自動化裝備,實現物理設備的互聯互通。通過加裝數據采集模塊,實時獲取設備運行狀態、生產進度等關鍵參數。
- 網絡傳輸層:部署5G專網、工業Wi-Fi或光纖網絡,構建低延遲、高可靠的內外網連接,確保數據的高速傳輸與交互。
- 平臺支撐層:搭建制造執行系統(MES)、企業資源計劃系統(ERP)等核心軟件平臺,實現生產計劃、物料管理、質量控制的數字化管理。
二、工業互聯網數據服務的集成與應用
工業互聯網數據服務為數字化車間提供核心驅動力,具體應用包括:
- 數據采集與邊緣計算:通過物聯網網關匯聚設備數據,在邊緣側進行初步清洗與處理,降低云端負載并提升響應速度。
- 云平臺數據分析:將處理后的數據上傳至工業互聯網平臺,利用大數據分析、機器學習算法挖掘數據價值,實現設備預測性維護、能耗優化、質量缺陷追溯等應用。
- 可視化監控與決策支持:通過數據駕駛艙、數字孿生等技術,將生產狀態以三維可視化形式動態呈現,輔助管理者實時掌握車間運行情況,快速做出生產調整決策。
三、實施路徑與注意事項
企業推進數字化車間建設需遵循“總體規劃、分步實施”原則:
1. 診斷評估階段:全面調研現有生產流程與設備狀況,明確數字化改造的重點環節與預期目標。
2. 試點示范階段:選擇關鍵產線或車間進行小范圍改造,驗證技術方案可行性,積累實施經驗。
3. 規模化推廣階段:在試點成功基礎上,逐步擴展至全車間,并持續優化數據服務應用模式。
實施過程中需重點關注數據安全防護,建立完善的權限管理與網絡安全體系,同時加強員工數字化技能培訓,確保技術與人才協同發展。
數字化生產車間與工業互聯網數據服務的深度融合,不僅能顯著提升制造效率與產品質量,更將推動企業從傳統生產模式向“數據驅動制造”的新范式轉型。制造型企業應把握技術發展趨勢,以數據為紐帶,構建敏捷、高效、智能的新型生產體系,在激烈市場競爭中贏得先機。